适用场景:
在机器学习中,决策树是一个预测模型,代表的是对象属性与对象值之间的一种映射关系。
算法思想:
决策树是一种常见机器学习方法中的一种分类器。它通过训练从有类别名称的训练数据集中学习得到一种类似于流程图的树结构。其中树内部每个非叶子节点表示在某个属性的判别条件对未知数据进行分类,每个分支表示该判别条件的一个输出,而每个叶子节点表示一个类别名称。树的首个节点是跟节点。
在决策树模型构建完成后,应用该决策模型对一个给定的,但类标号未知的元组X进行分类是通过测试该元组X的属性值,得到一条由根节点到叶子节点的路径,而叶子节点就存放着该元组的类预测。这样就完成了一个未知类标号元组数据的分类,同时决策树也可以表示成分类规则。
决策树包括:根结点、若干个内部结点、若干个叶节点(即目标分类节点)。

案例1:
夏日炎炎,我们是如何使用过去买瓜的经验来判断一个西瓜的好坏?一般会根据它的色泽、根蒂、敲声、纹理、 触感等等来判断它是不是一个好瓜。
接下来,就用这个例子来看看AI技术是如何完成这个任务。
以下收集的是一些西瓜的数据:包含西瓜的色泽、根蒂、敲声等数据。
对于“这个西瓜好吗?甜吗?”这样的问题,通常会进行一系列判断或“子决策”,我们先看“西瓜是什么颜色?”, 如果是青绿色再看它的根蒂是什么形状,如果是蜷缩,再判断敲击的声音,最后得出最终决策:这是个好瓜。
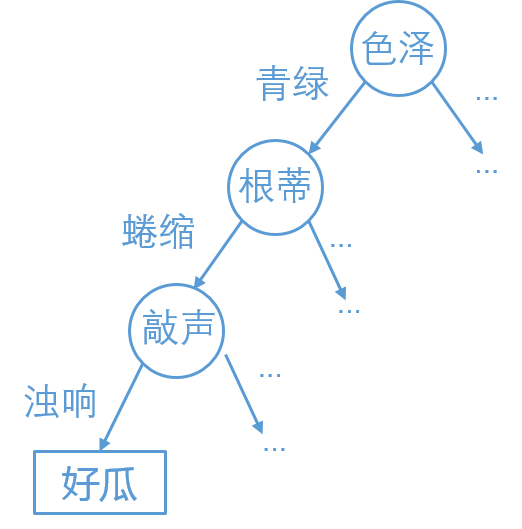
数据中的色泽、根蒂等就是属于西瓜的特征,用西瓜的特征来判断西瓜的好坏这是十分自然的想法,但是为什么是这个顺序呢?为什么先判断色泽,再来看根蒂呢?

如果对决策树并不了解的同学,应该能猜到色泽这个特征大概率能判别出西瓜的好坏。
我们现在就来讨论一下这个判别标准是什么,因为不能单纯靠经验来做这个判断,要严谨的数理论证来使得这一点能成立,确定 色泽这一特征的确比其他特征对判断西瓜的好坏有更大的作用。
决策树生成算法ID3
在西瓜数据集里面包含了17个训练样例,有两个结果类别,好瓜和坏瓜。好瓜比例为8/17,坏瓜比例为9/17,则根节点的信息熵为0.998,计算过程如下:
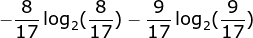
在色泽、根蒂、敲声等8个特征中选定一个作为决策树的第一个节点,这里以色泽为例:其中分为三类青绿、浅白、乌黑, 在青绿色这一类别中包括了第1、4、6、10、13、17项,共6个实例(6/17),其中好瓜占比3/6,坏瓜占比3/6,其他颜色同理可求。
Ent(青绿)=1.000,Ent(浅白)=0.918,Ent(乌黑)=0.722,最后计算色泽特征信息量的过程如下:
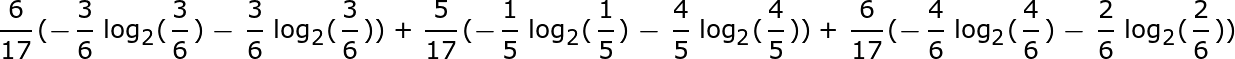
得出Gain(D,色泽)=0.109,用同样的方法可以求得Gain(D,根蒂)=0.143、Gain(D,敲声)=0.141、Gain(D,纹理)=0.381、 Gain(D,脐部)=0.289、Gain(D,触感)=0.006
观察计算出的结果,在这里纹理的信息熵增益最大,因此选择纹理特征作为根节点,由此生成一颗决策树。
案例2:
银行希望能够通过一个人的信息(包括职业、年龄、收入、学历)去判断他是否有贷款的意向, 从而更有针对性地完成工作。下表是银行现在能够掌握的信息,我们的目标是通过对下面的数据进行分析建立一个预测用户贷款一下的模型。
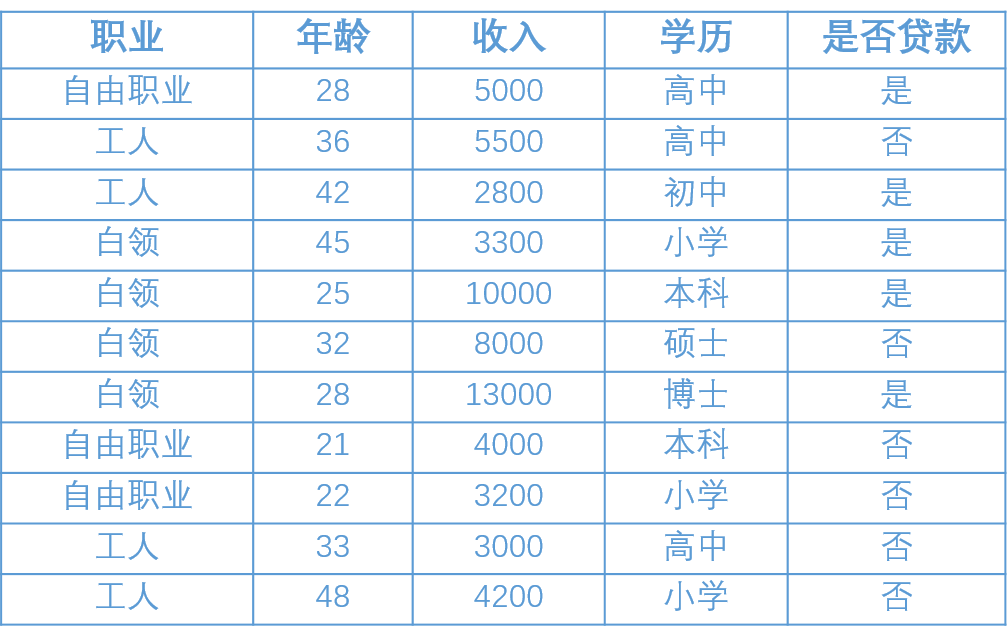
上边中有4个客户的属性,如何综合利用这些属性去判断用户的贷款意向?决策树的做法是每次选择一个属性进行判断 ,如果不能得出结论,继续选择其他属性进行判断,直到能够“肯定地”判断出用户的类型或者是上述属性都已经使用 完毕。比如说我们要判断一个客户的贷款意向,我们可以先根据客户的职业进行判断,如果不能得出结论,再根据年 龄作判断,这样以此类推,直到可以得出结论为止。
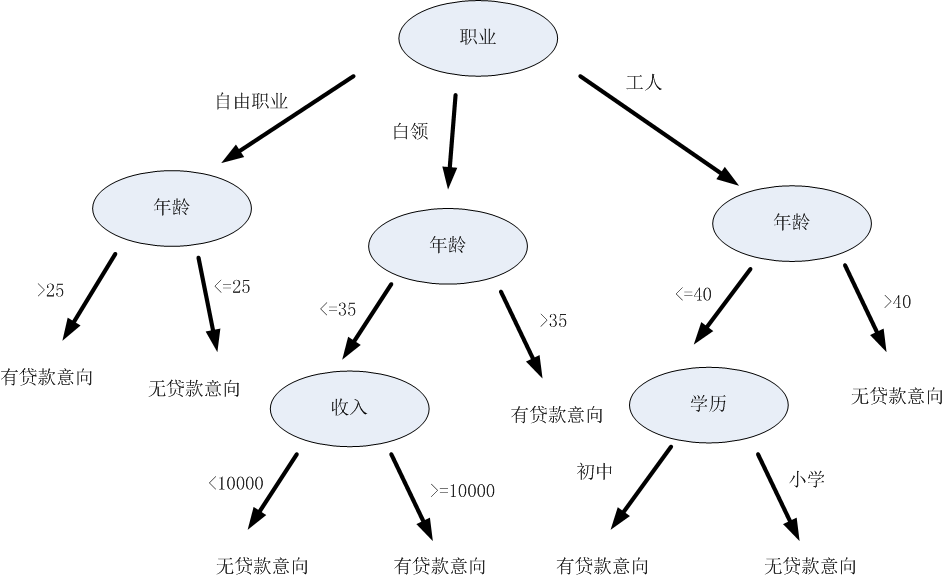
通过上面的决策树,就能根据用户的职业、收入、年龄以及学历就可以分析得出用户的类型。比如某客户的信息为: {职业、年龄,收入,学历}={工人、39, 1800,小学},将信息输入上述决策树,可得出该客户无贷款意向的结论。
那么构建出上图的决策树要经过下面这几个步骤:
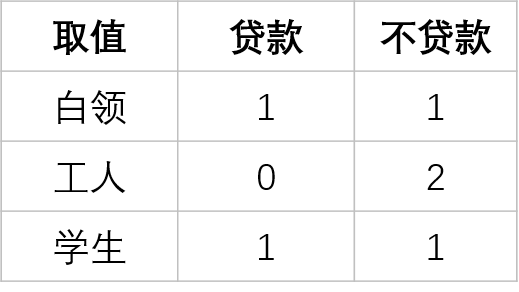
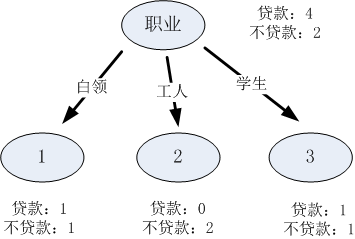
比如下面左图的表中“职业”是离散型变量,有三个取值,分别为白领、工人和学生,根据三个取值对原始的数据进行分割。可以表示成最右侧的那张图。

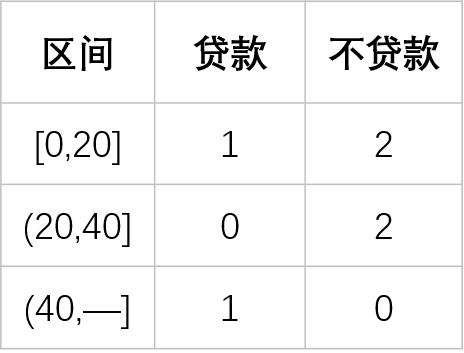
若使用“年龄”连续性变量将数据分成三个区间,就可以分别设置区间[10,20]、[20,30]、[30,40],则每一个区间的分割结果如下:
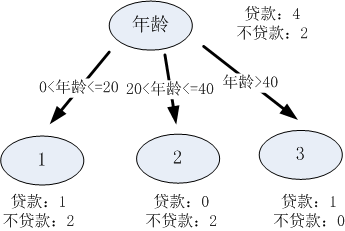
接着以熵作为节点复杂度的统计量,分别求出下面例子的信息增益,假设有属性1和属性2,通过计算这两个属性分类后的信息增益,选择最优的分类属性。

通过计算信息增益可以得出属性1与属性2相比是更优的分裂属性,故选择属性1作为优先分类的属性。
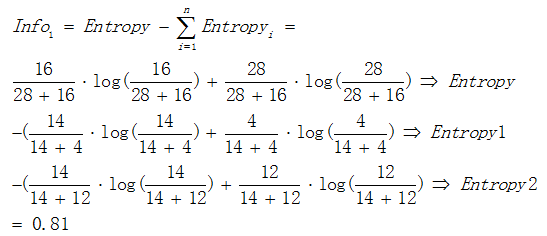
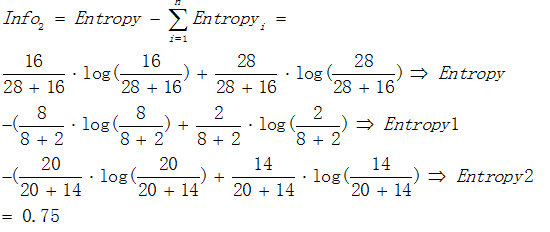
最后就是选择停止分类的一遍条件:
根据决策树的输出结果,决策树可以分为分类树和回归树,分类树输出的结果为具体的类别,而回归树输出的结果为一个确定的数值。
决策树的构建算法主要有ID3、C4.5、CART三种,其中ID3和C4.5是分类树,CART是分类回归树。 其中ID3是决策树最基本的构建算法,而C4.5和CART是在ID3的基础上进行优化的算法。
补充说明:
决策树是一类常见的机器学习方法,希望从给定数据集中学得一个模型用以对新的对象进行分类。我们可以将这个 过程看做对“当前对象属于某类吗?”这个问题的“决策”或“判定”的过程。
所谓决策树可以把它看成是一堆决策,这些决策就像是我们在写代码时的if else语句,将数据输入决策树时就通过 了一堆if else的判断,最终在判断的终点决策时就会返回给我们一个答案。
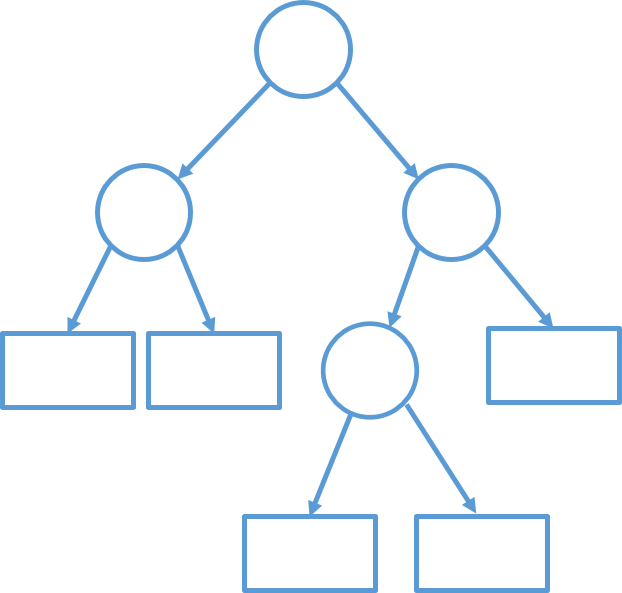
图中每一个圆形节点都代表了一个决策过程,可以认为是一个if的判断,而矩形的节点则可以看成是一个返回的
结果,通过一些列不同的判断走向,决策树会对输入数据返回相对应的输出,这就是决策树的作用。
对分类而言
就是根据输入数据来对他的有用的特征进行逐层的判断,每一层的判断都建立在上一层的判断之上,最终得出结论。
算法优点
算法缺点
关于优必杰教育 | 擎课堂 | AI教学平台 | 嘉定集散地 | 余杭集散地 | 常用工具
©2017-2020 上海优必杰教育科技有限公司 · 沪ICP备17047230号-3
