适用场景:
K-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。主要用于聚类分析、预测分析、文本分类、降维等。典型应用场景有客户流失预测、欺诈侦测等(更适合于稀有事件的分类问题)。
算法思想:
存在一个训练样本集,我们知道样本集中的每一个数据与所属分类的对应关系,输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应特征进行比较,然后算法提取样本集中特征最相似的数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处。通常k是不大于20的整数。
kNN算法的基本法则是:相同类别的样本之间在特征空间中应当聚集在一起,对于给定测试样本,基于某种距离度量找出训练集中与其最靠近的K个训练样本,或者指定距离e之内的训练样本,然后基于这K个“邻居”的信息来进行预测,分类任务中通过投票法(以及加权投票等)将出现最多的类别标记作为预测结果,回归任务中则使用平均法(以及加权平均等)。
其算法的描述为:
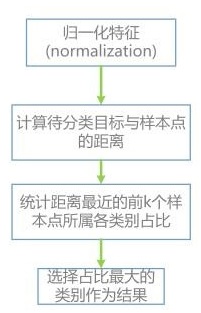
案例1:
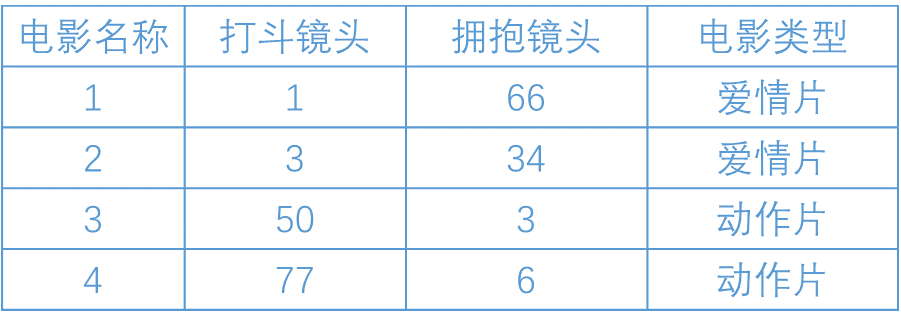
利用k-近邻算法判断一部电影是动作片还是爱情片。下面有一些数据,这些数据都有两个特征,即打斗镜头数和拥抱 的镜头数。除此之外,也可以知道每个电影的类型,即分类标签。
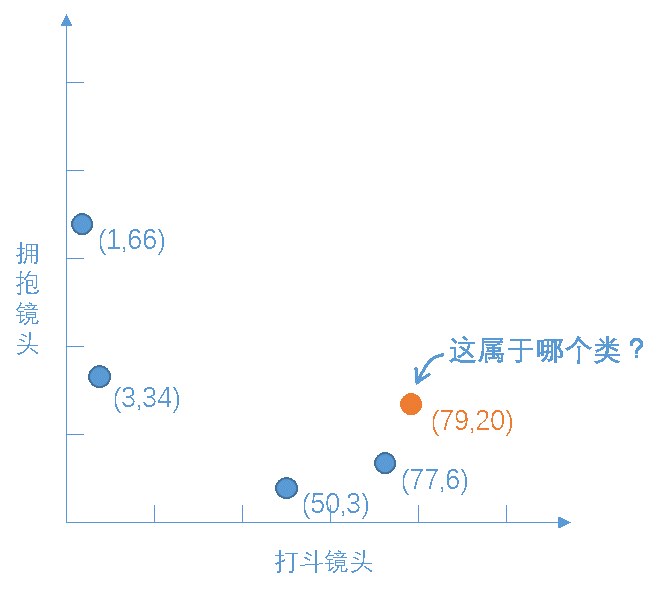
kNN是根据特征比较,将数据集映射到新的空间后,可以从图中大致推断,这个橙色圆点标记的电影可能属于动作片, 因为距离已知的那两个动作片的圆点更近。
那么实际实际使用KNN算法时,是用距离进行度量的。在这个电影分类中有2个特征,可以使用两点距离公式计算与样本数据的距离。
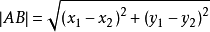
通过计算,可以得到如下结果:
(79,20)->爱情片(1,66)的距离约为90.55385138137417
(79,20)->爱情片(3,34)的距离约为77.27871634544663
(79,20)->动作片(50,3)的距离约为33.61547262794322
(79,20)->动作片(77,6)的距离约为14.142135623730951
现在k值取3,那么在这个例子中,按距离依次排序的三个点分别是动作片(77,6)、动作片(50,3)、爱情片(3,34)。 在这三个点中,动作片出现的频率为三分之二,爱情片出现的频率为三分之一,所以该橙色圆点标记的电影为动作片, 这个判别过程就是k-近邻算法。
案例2:
利用k近邻算法让计算机识别数字,要先对数字图像做预处理以及特征提取。
数字图片上的数据灰度值基本都是75或76,所以只需把灰度值等于75或76的赋为1,其余的为0即可,就可以完成二值化利于后续提取特征进行判别。
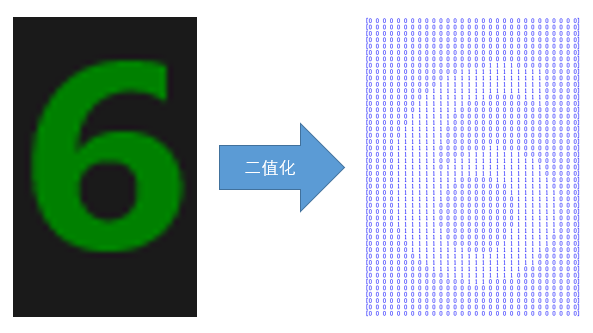
接着对图片进行切割后,准备提取出每个图片的特征。图像的特征很多,这个案例中选取1占所在区域的比例作为图片特征。
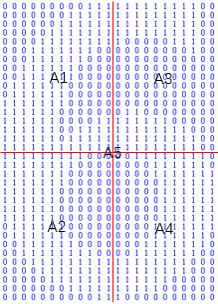
计算左上部分1所占的比例A1、左下部分1所占的比例A2、右上部分1所占的比例A3、右下部分1所占的比例A4和所有1占整副图的比例A5。这样,就提取出了此幅图的特征向量A=[A1,A2,A3,A4,A5]。
利用kNN算法的具体实现步骤如下:
补充说明:
算法优点
算法缺点
关于优必杰教育 | 擎课堂 | AI教学平台 | 嘉定集散地 | 余杭集散地 | 常用工具
©2017-2020 上海优必杰教育科技有限公司 · 沪ICP备17047230号-3
