适用场景:
用于数据集内种类属性不明晰,希望能够通过数据挖掘出或自动归类出有相似特点的对象的场景。主要应用于数据挖掘领域,大量应用于天文学,商务,生物学,地质统计学等,作为其他算法的预处理过程。其商业界的应用场景一般为挖掘出具有相似特点的潜在客户群体以便公司能够重点研究、对症下药。
算法思想:
将某一些数据分为不同的类别,在相同的类别中数据之间的距离应该都很近,也就是说离得越近的数据应该越相似,再进一步说明,数据之间的相似度与它们之间的欧式距离成反比。这就是k-means模型的假设。
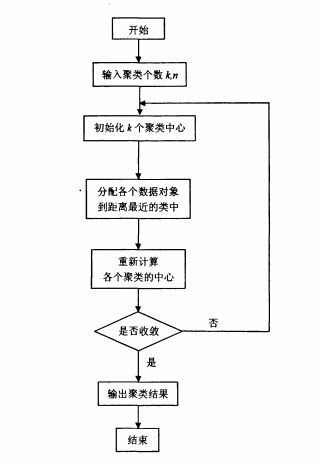
k-means算法首先随机选取k个点作为初始聚类中心,然后计算各个数据对 象到各聚类中心的距离,把数据对象归到离它最近的那个聚类中心所在的类; 调整后的新类计算新的聚类中心,如果相邻两次的聚类中心没有任何变化,说明 数据对象调整结束,聚类准则函数f已经收敛。在每次迭 代中都要考察每个样本的分类是否正确,若不正确,就要调整。在全部数据调整 完后,再修改聚类中心,进入下一次迭代。如果在一次迭代算法中,所有的数据 对象被正确分类,则不会有调整,聚类中心也不会有任何变化,这标志着f已 经收敛,算法结束。其实这跟普通的前馈神经网络使用逆向传播算法训练模型的原理类似,分析误差,修改模型直至达到要求的误差范围。
其算法过程描述为:
案例1:
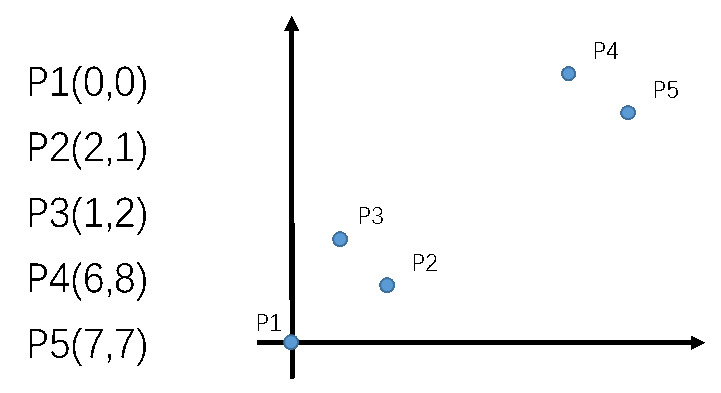
如下图所示,将给定的一组数据在坐标中表示,从图中可以看出有两堆点,我们用聚类的思想执行k-means,看看结果和预期是否一致。
第一步,任意选择初始点P1和P2,利用勾股定理计算其它点到初始点的距离,如图所示。经过计算可以得出P3、P4、P5和P2更近, 所以得到第一次分类结果:

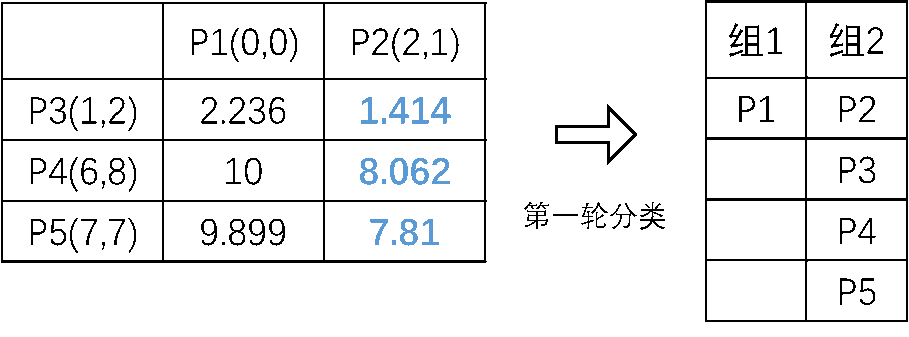
第二步,在组2中重新选择一个点P6,计算与其它点的距离,P6是由组2中所有点的X坐标和Y坐标的平均值组成,如图所示。再次计算距离并分组, 得到第二次分组结果,

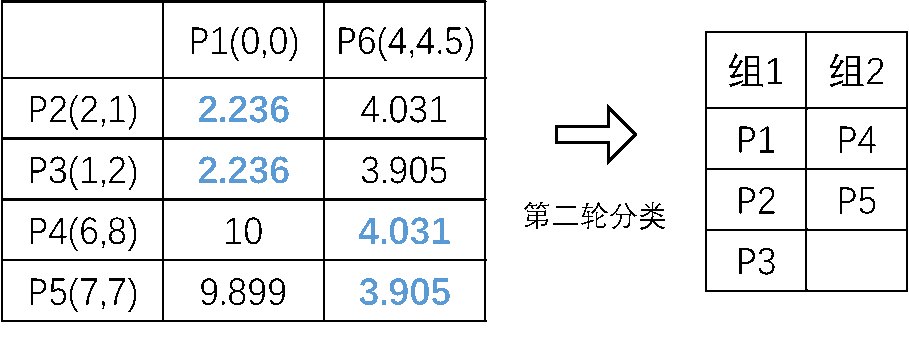
第三步,从两组数据集中再计算出两个新的点,如图所示,计算所有点到P7和P8的距离,将得到分组结果和第二次的分 组结果进行比较
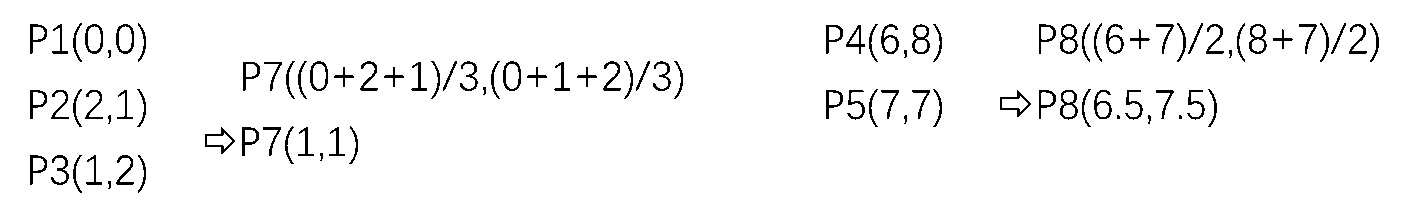

最后可以发现,第三步和第二步结果没有任何变化了,说明聚类结束。聚类结果和开始设想的结果一致。

补充说明:
算法优点
算法缺点
关于优必杰教育 | 擎课堂 | AI教学平台 | 嘉定集散地 | 余杭集散地 | 常用工具
©2017-2020 上海优必杰教育科技有限公司 · 沪ICP备17047230号-3
