适用场景:
多用于二分类或多分类的应用场景,用于做分类任务的基础。例如:人脸识别、文本/视频分类、表情识别等
算法思想:
通过学习多个弱分类器,每一轮学习新的弱分类器,最终对这些弱分类器进行加权求和,构成一个更强的最终分类器(强分类器)。训练时,训练样本也有权重,在训练过程中动态调整,被前面的弱分类器错分的样本会加大权重,反之减小权重,因此算法会关注难分的样本。最终分类器中将加大分类错误率小的弱分类器权重,使其在表决中起较大的作用,减小分类误差率大的弱分类器权重,使其在表决中起较小的作用。

Adaboost也称Adaptive Boosting算法(自适应boosting算法),它的自适应在于:前一个基本分类器分错的样本会得到加强,加权后的 全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先 指定的最大迭代次数。
下图中的“+”和“-”分别表示两种类别,在这个过程中,我们使用水平或者垂直的直线作为分类器,来进行分类。
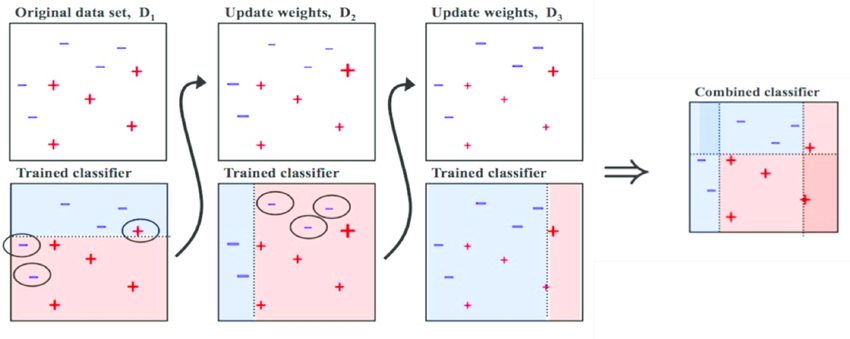
案例1:
每个弱分类器类似于一个水平不太高的医生,如果在之前的考核中一个医生的技术更好,对病人情况的判断更准确,那么可以加大他在会诊时说话的分量即权重。而强分类器就是这些医生的结合。
案例2:
给定如下表所示的训练数据。假设弱分类器由x< v或 x>v产生,其阈值使该分类器在 训练数据集上分类误差率最低。试用AdaBoost算法学习一个强分类器

训练第1个基分类器:
在权值分布为D1的训练数据上,阈值v取2.5时分类误差率最低,故基本分类器为:

显然序号为7、8、9数据产生了错误。G1(x)在训练数据集上的误差率等于将这3个数据的权值相加:
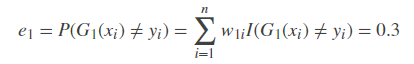
*注意:I(G1(xi)≠yi)表示当G1(xi)不等于yi时 函数I()的值为1,等于时值为0。这里只有i=7,8,9时函数I值为1,其余为0。
计算G1(x)的系数
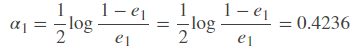
更新训练数据的权值分布(分类器sign[f1(x)]在训练数据集上有3个误分点。 ):

训练第2个基分类器:
在权值分布为D2的训练数据上,阈值v取8.5时分类误差率最低,故基本分类器为:
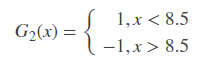
显然序号为4、5、6数据产生了错误。G2(x)在训练数据集上的误差率等于将这3个数据的权值相加:
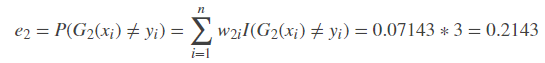
*注意:I(G2(xi)≠yi)表示当G2(xi)不等于yi时 函数I()的值为1,等于时值为0。这里只有i=4,5,6时函数I值为1,其余为0。 。
计算G2(x)的系数
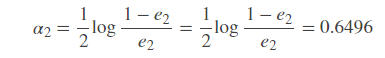
更新训练数据的权值分布:
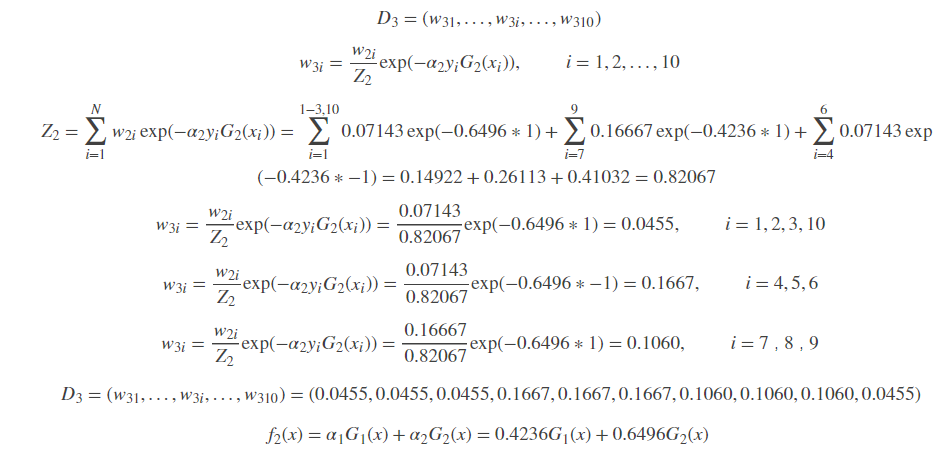
训练第3个基分类器:
在权值分布为D3的训练数据上,阈值v取5.5时分类误差率最低,故基本分类器为:
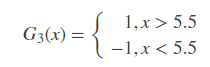
显然序号为1、2、3、10的数据产生了错误。G3(x)在训练数据集上的误差率等于将这4个数据的权值相加:

*注意:I(G3(xi)≠yi)表示当G3(xi)不等于yi时 函数I()的值为1,等于时值为0。这里只有i=1,2,3,10时函数I值为1,其余为0。
计算G3(x)的系数

更新训练数据的权值分布:
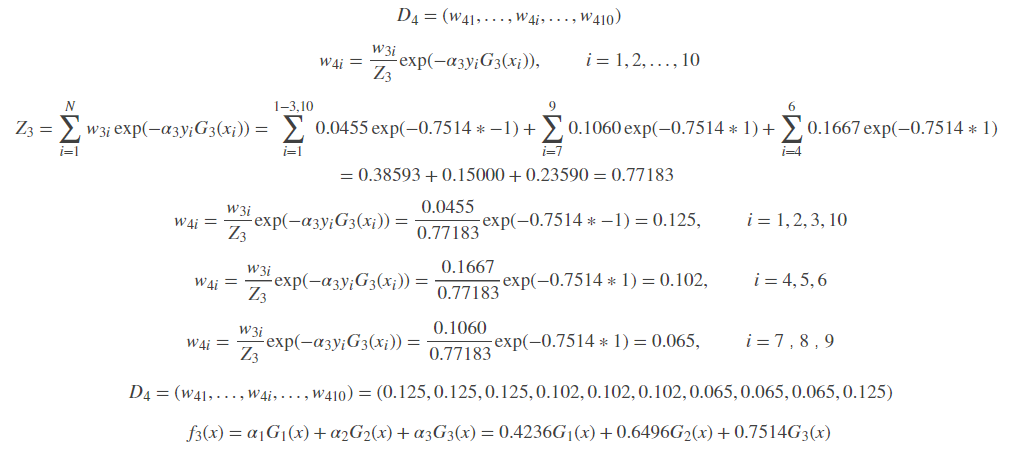
分类器sign[f3(x)]在训练数据集上有0个误分点,于是最终分类器为:
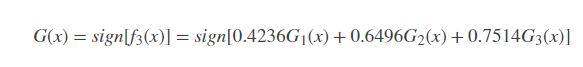
补充说明
集成学习(ensemble learning)是通过合并多个模型来提升机器学习性能,完成学习任务,早期使用这种方法相较于当个单 个模型通常能够获得更好的预测结果,集成学习方法分两大类:
集成学习也可以借用“盲人与大象”的故事来理解: 所有盲人摸过大象后对大象都有自己的描述,即使每个描述都是正确的,最好还是在一起讨论它们的含义,然后得出最终结论。 重复进行上述步骤,直至基于学习器数目达到事先指定的值,最终将这几个基学习器进行加权结合。

1989年Kearns和Vallant提出的理论问题“weakly learnable”?=” strongly earnable”,设想有没有办法把一个比随机猜测好一点的弱学习算法变成非常精确的强学习算法。 接着在1990,Schapire就提出了一个构造性证明,证明了等式其实是可以成立的,这个方法就是boosting算法。而在1993年Freund提出了用投票算法结合多个弱学习器的算法。 有了这两个算法思想的支撑,1995年就发表了boosting算法的改进版——Adaboost(adapt boosting)算法。直到1997年Freund和Schapire共同发布了具有实际使用价值的Adaboost算法。
算法优点
算法缺点
关于优必杰教育 | 擎课堂 | AI教学平台 | 嘉定集散地 | 余杭集散地 | 常用工具
©2017-2020 上海优必杰教育科技有限公司 · 沪ICP备17047230号-3
