适用场景:
MDP被用于机器学习中强化学习问题的建模。通过使用动态规划、随机采样等方法,MDP可以求解使回报最大化的智能体策略 ,并在自动控制、推荐系统等主题中得到应用。
算法思想:
马尔科夫决策过程是马尔科夫链的扩展,在原基础上加入了行动(Action)和奖励/反馈(Reward)。相应的转移矩阵也产生了变化,下一个状态的概率分布不仅取决于上一个状态还取决于采取的行动。而从环境得到的反馈则告诉我们这一步到底是好(正向反馈)还是坏(负向反馈),下次就可以避免在同一状态下采取同样的行动。那么最终在不断最大化奖励的过程中,就获取了最优策略。
MDPs 简单说就是一个智能体(Agent)采取行动(Action)从而改变自己的状态(State)获得奖励(Reward)与环境(Environment)发生交互的循环过程。 一个马尔可夫决策过程由一个四元组构成(S, A, Psa, R):
MDP的动态过程如下:
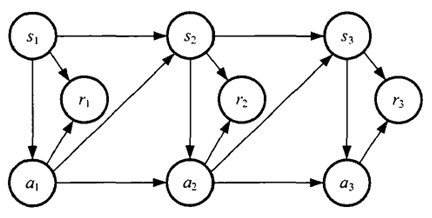
某个智能体(agent)的初始状态为s0,然后从 A 中挑选一个动作a0执行,执行后,agent 按Psa概率随机转移到了下一个s1状态,s1∈
Ps0a0。然后再执行一个动作a1,就转移到了s2,接下来再执行a2…,我们可以用下面的图表示状态转移的过程。

如果回报r是根据状态s和动作a得到的,则MDP还可以表示成下图:
MDP包含以下三层含义:
案例:

补充说明
算法优点
关于优必杰教育 | 擎课堂 | AI教学平台 | 嘉定集散地 | 余杭集散地 | 常用工具
©2017-2020 上海优必杰教育科技有限公司 · 沪ICP备17047230号-3
