这个demo是利用Q Learning算法玩一个游戏,里面有一个智能体(agent),它有9个分别感知到墙的距离、到绿色或红色物体 的距离。智能体吃掉红色物体就会得到回报,吃掉绿色有毒的东西,就会得到负面惩罚。
适用场景:
不需要大量的“数据喂养”,而是通过自己不停的尝试来学会某些技能。最大的应用场景是游戏,例如围棋、Dota。
算法思想:
Q Learning算法是以得到最优奖励为目的选择行为的算法Q即Q(s,a),是在某一时刻的 s 状态下,采取行为a动作能 获得期望奖励,环境会根据agent的动作反馈相应的回报r,所以算法的主要思想就是将s与a构建成一张Q-table来存 储Q值,然后根据Q值来选取能够获得最大的收益的动作。一开始Q表里是随机设置的,称为估计值,而算法的目的就 是更新Q表,使之变成一个准确的Q表。
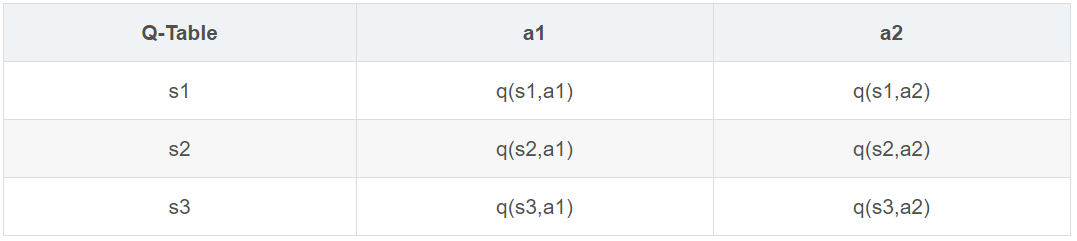
Q-Learning算法流程描述为:
案例1:
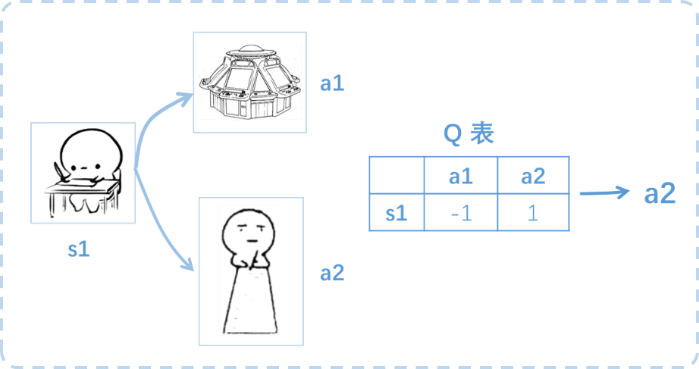
用一个场景来了解Q learning的算法过程,小时候贪玩没写完作业就要玩游戏、看电视,家长通常会告诉你要先做 完作业才能玩。那么到底是现在就去玩还是继续写作业呢,这就是个决策过程。

假设行为准则已经学习好了, 现在处于s1写作业状态,我有两个行为 a1,a2,分别是看电视和写作业,根据我的经验 ,在这种 s1 状态下,a2 写作业带来的潜在奖励要比 a1 看玩游戏高,这里的潜在奖励我们可以用一个有关于 s 和 a 的 Q 表格代替,Q(s1, a1)=-1 要小于 Q(s1, a2)=1,所以判断要选择 a2 作为下一个行为。
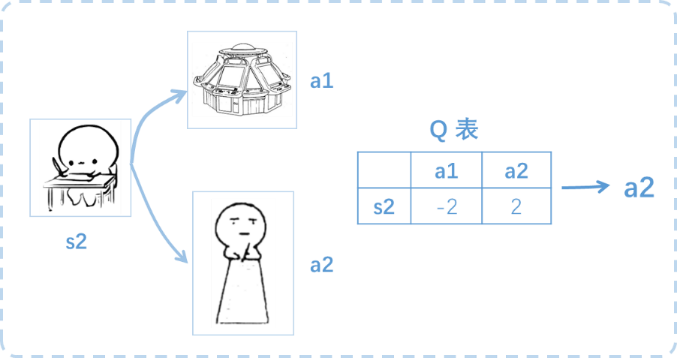
接着将目前的状态更新成 s2 , 还是有两个同样的选择, 重复上面的过程, 在行为准则Q 表中寻找 Q(s2, a1) Q(s2, a2) 的值, 并比较它们的大小, 选取较大的一个。 接着根据 a2 可以到达 s3 并重复上面的决策过程,Q learning 的方法也是这样决策的。
了解完Q learning的决策过程,接下来研究一下这张行为Q 表是通过什么样的方式更改提升的。上述决策过程中在s1 状态下选择了a2行为并到达 s2状态, 此时更新了Q 表,随后并没有在实际中采取任何行为,而是我们想象在 s2状态 时采取了每种行为。
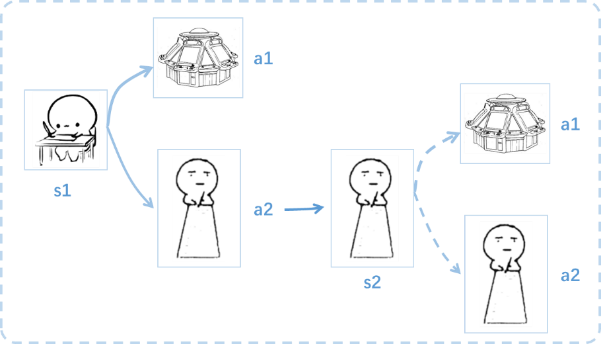
使用Q learning方法在更新Q表时,就不仅仅是比较一下Q值大小了,会进行接下来的计算: 比如Q(s2, a2) 的值比 Q(s2, a1) 的大, 会把大的 Q(s2, a2) 乘上一个衰减值 γ(比如0.9) 加上到达s2时所获取的奖励 R (因为还没获得最后的奖励,所以是 0),把这个作为 Q(s1, a2) 的值。再结合现在计算出的值和之前估计的值, 就能更新Q(s1, a2) 了, 根据估计与现实的差距, 将这个差距乘以一个学习效率 α 累加上之前的 Q(s1, a2) 的值变成新的值。 这里虽然用 maxQ(s2) 估算了一下 s2 状态,但还没有在 s2 做出任何的行为,s2 的行为决策要等到更新完了以后再重新另外做。这就是Q learning学习优化决策的一种过程。
案例2:
假设有这样的房间,如果将房间表示成点,然后用房间之间的连通关系表示成线,像下面右图一样。

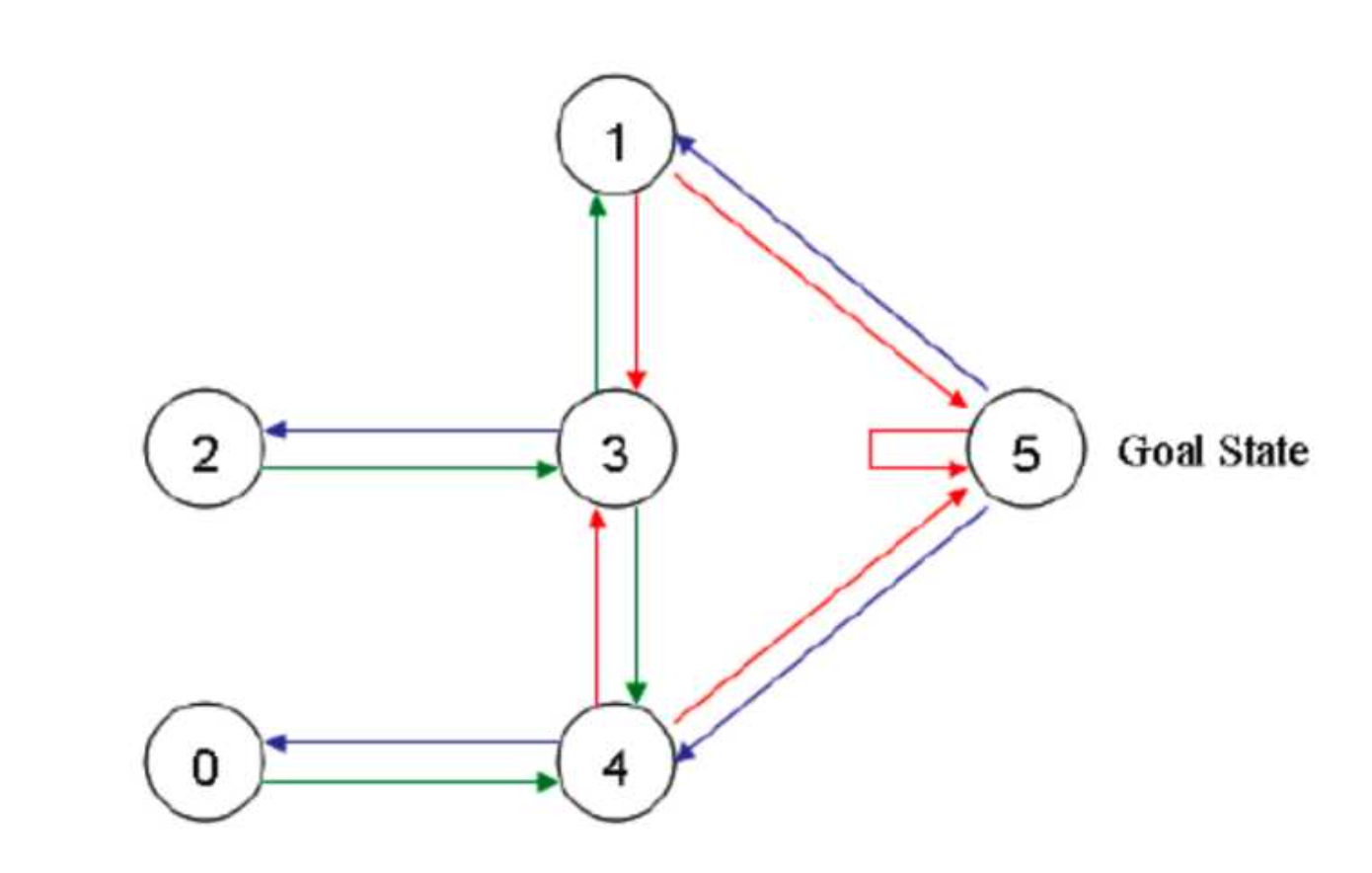
首先将agent(机器人)处于任何一个位置,让他自己走动,直到走到5房间,表示成功。为了能够走出去,我们将每个节点之间设置一定的权重,能够直接到达5的边设置为100,其他不能的设置为0,这样网络的图:
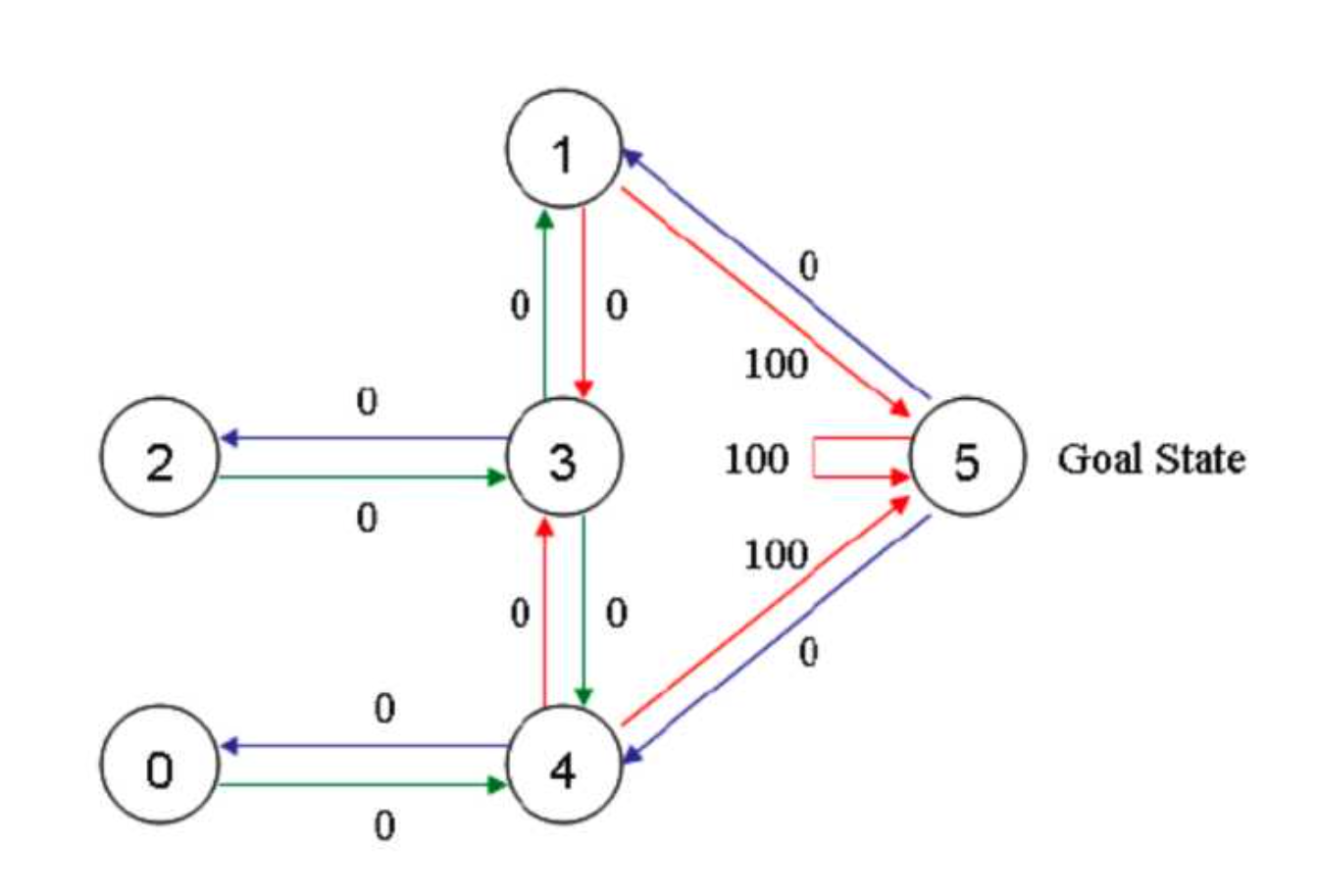
Qlearning中,最重要的就是“状态”和“动作”,状态表示处于图中的哪个节点,比如2节点,3节点等等,而动作则表示从一个节点到另一个节点的操作。
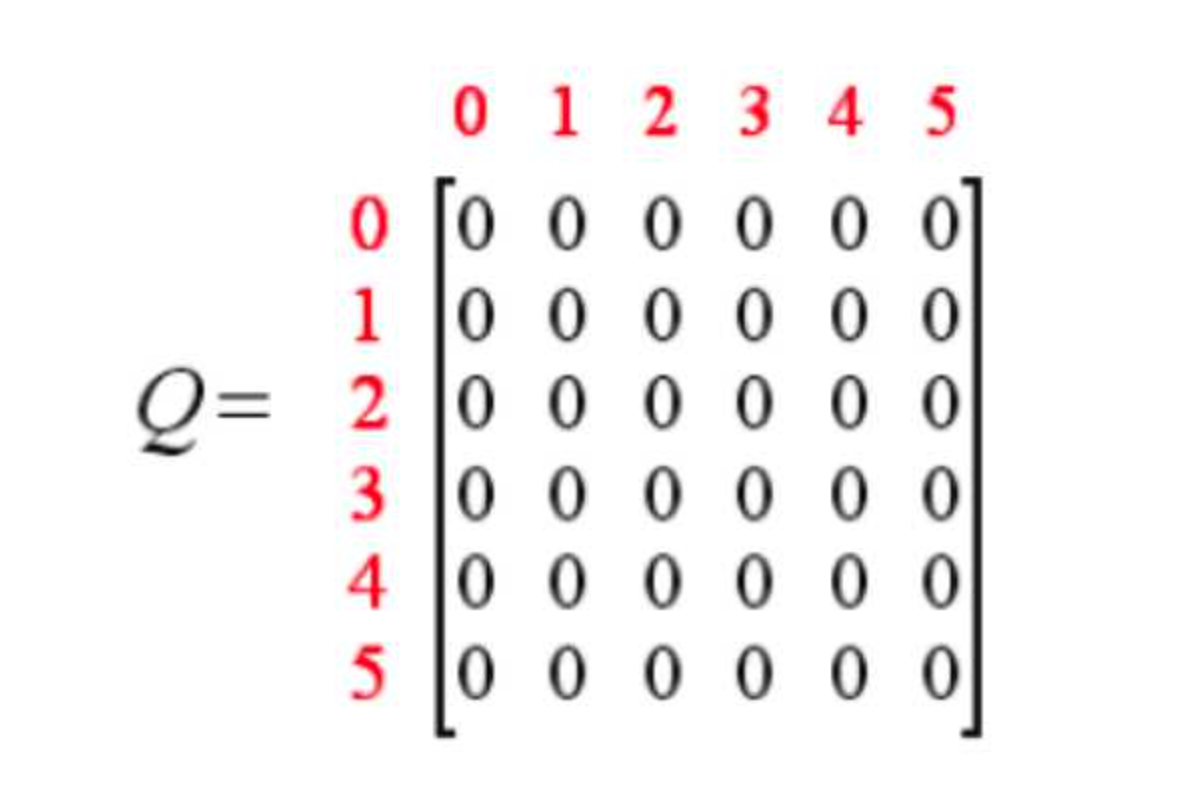
接下来就可以生成一个奖励矩阵矩阵,矩阵中,-1表示不可以通过,0表示可以通过,100表示直接到达终点。同时,创建一个Q表,表示学习到的经验,与R表同阶,初始化为0矩阵,表示从一个state到另一个state能获得的总的奖励的折现值。

Q表中的值根据如下的公式来进行更新: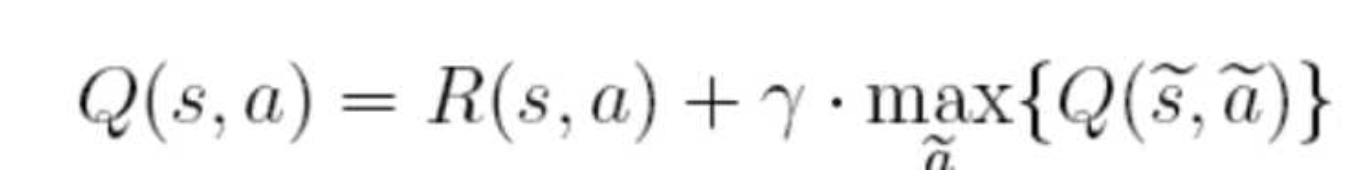
在上面的公式中,S表示当前的状态,a表示当前的动作,s表示下一个状态,a表示下一个动作,λ为贪婪因子,0< λ <1,一般设置为0.8。Q表示的是,在状态s下采取动作a能够获得的期望最大收益,R是立即获得的收益,而未来一期的收益则取决于下一阶段的动作。
所以,Q-learning的学习步骤可以归结为如下:

在迭代到收敛之后,我们就可以根据Q-learning来选择我们的路径走出房间,假设λ=0.8,奖励矩阵R和Q矩阵分别初始化为:


随机选择一个状态,比如1,查看状态1所对应的R表,也就是1可以到达3或5,随机地,我们选择5,根据转移方程:
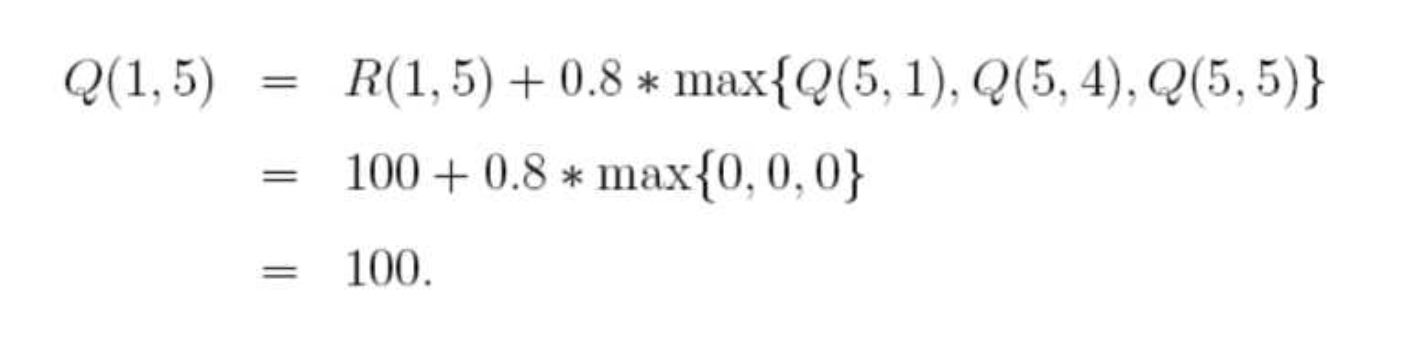
于是,Q表为:

这样,到达目标,一次尝试结束。
接下来再选择一个随机状态,比如3,3对应的下一个状态有(1,2,4都是状态3对应的非负状态),随机地,我们选择1,这样根据算法更新:
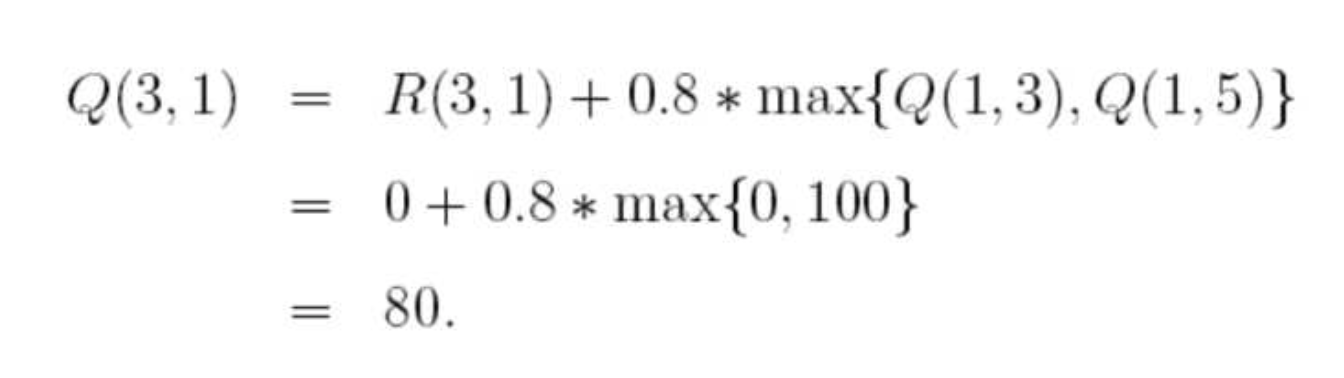
这样,Q表就更新为如下左图所示,经过不停的迭代,最终的Q表如下右图所示:
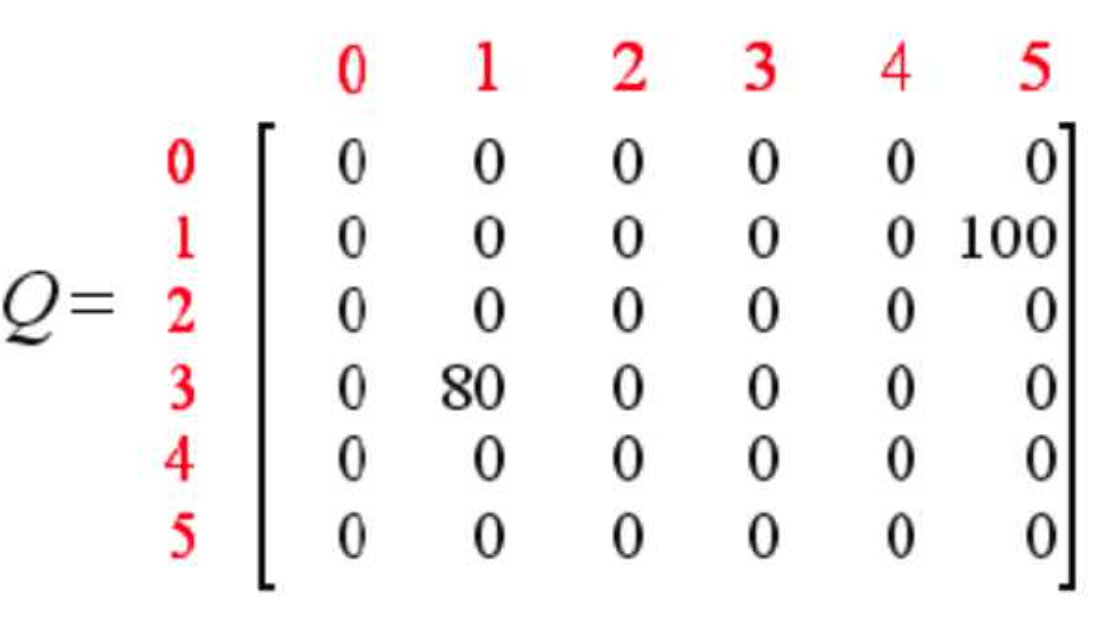

将Q表中的数转移到我们一开始的示意图中就像这样:
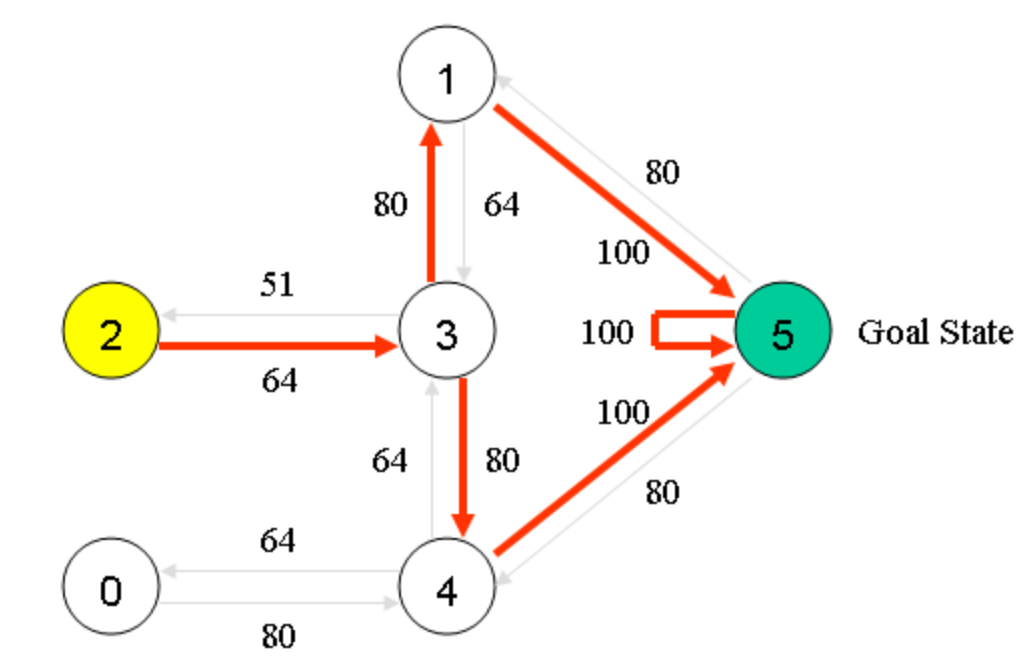
在得到Q表之后,我们可以根据如下的算法来选择我们的路径:
举例来说,假设我们的初始状态为2,那么根据Q表,我们选择2-3的动作,然后到达状态3之后,我们可以选择1,2,4。但是根据Q表,我们到1可以达到最大的价值,所以选择动作3-1,随后在状态1,我们按价值最大的选择选择动作1-5,所以路径为2-3-1-5。
补充说明
强化学习是机器学习大家族中的一大类, 是一个重要分支,它的本质是解决 decision making 问题,即自动进行决策,并且可以做连续决策。使用强化学习能够让机器学着如何在环境中拿到高分, 表现出优秀的成绩. 而这些成绩背后却是他所付出的辛苦劳动, 不断的试错, 不断地尝试, 累积经验, 学习经验。 它主要包含几个关键要素:agent(智能体),reward(奖励),action(行为),state(状态),environment(环境), 强化学习的目标就是获得最多的累计奖励。
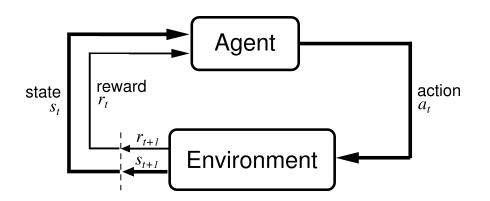
以小孩学习走路来做个形象的例子: 小孩想要走路,但在这之前,他需要先站起来,站起来之后还要保持平衡,接下来还要先迈出一条腿,是左腿还是右腿,迈出一步后还要迈出下一步。
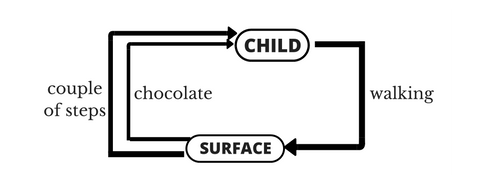
小孩就是agent,他试图通过采取行动(即行走)来操纵环境(行走的表面),并且从一个状态转变到另一个状态(即他走的每一步),当他完成任务的子任务(即走了几步)时,孩子得到奖励(给巧克力吃),并且当他不能走路时,就不会给巧克力。
强化学习是算法族, 包含了很多种算法, 从agent智能体的角度可以分成三大类:以得到最优奖励为目的选择行为;选择最优策略选择行为;关注每一步的最优行动。
关于优必杰教育 | 擎课堂 | AI教学平台 | 嘉定集散地 | 余杭集散地 | 常用工具
©2017-2020 上海优必杰教育科技有限公司 · 沪ICP备17047230号-3
